
This course explains the system design for a paste bin service, covering functional and non-functional requirements, capacity estimation, database schema, and a distributed key generation service.
Highlights
- Functional Requirements: Users can paste text, share via custom links, and set expiry dates.
- Non-Functional Requirements: Focus on durability, high availability, and low latency for optimal user experience.
- Capacity Estimation: Assumes 100k users daily, with calculations for read/write traffic and data storage needs.
- Hybrid Storage Approach: Uses a mix of database and cloud storage (e.g., S3) for efficient data handling.
- Unique Key Generation: A distributed service ensures unique paste identifiers, avoiding predictable sequences.
- Paste Expiry Management: An asynchronous cleanup service deletes expired pastes from the database and cloud storage.
- Scalable Architecture: Utilizes serverless functions or containers to handle traffic efficiently, including caching strategies.
Key Insights
- Importance of Requirements: Clearly defining functional and non-functional requirements is crucial for effective system design, ensuring both user satisfaction and system performance.
- Traffic Analysis: Understanding user traffic patterns helps in estimating system load, guiding infrastructure scaling and resource allocation.
- Data Storage Strategy: A hybrid approach balances performance and cost, utilizing both databases for small data and cloud storage for larger blobs, optimizing data retrieval times.
- Caching Mechanisms: Implementing caching can significantly reduce database load and improve response times, especially in read-heavy applications.
- Dynamic Key Generation: The use of a distributed key generation service prevents ID collisions and maintains performance, essential for high-volume systems.
- Data Expiration Processes: Regular cleanup of expired data is vital for resource management and cost efficiency, especially in cloud environments.
- Scalable Solutions: Adopting a serverless architecture or microservices allows for better scalability and flexibility, accommodating fluctuating user demands effectively.
Architecture
Intro
First, we need to understand the functional and non-functional requirements non-functional requirements icing. All the behavior of your software architecture and the functional requirements are the business requirements.
So the business requirements are first one. Obviously, users should be able to paste the text and share to other users by using a customized link or opportunity link. So that’s the first requirement, and also there is a limit of maximum text. Size should be 10 mb. This is usually your business requirement and business requirements will drive the system design. So it’s very important to properly gather all the business requirements and the second one is: users should be able to have his own custom. Url say if you have a domain of say: paste bin com user should be able to give this part, and obviously, when the user visits to that specific path, the same text should be appear and the next one is paste expiry. So by default the business requirement. Let’s assume the paste should expire after 6 month, but user should be able to customize that as well and the fourth one is users should be able to log in and see all of his specific tastes or diffusor is not logged in you should try to you, know, aggregate or attach those paste to an anonymous user created for that specific session or a browser where you have dropped your cookies and the next thing is understanding the non-functional requirements, so there are functional dependence for pastebin.
om is first one is durability, because once you write that data, it should be always be there. It’s not like you write the data to the system like pastebin.com and then, when you visit, that means the data is not found or something those those errors shouldn’t be there, so the system should be 100%, durable and the second one is high availability and the third one is low: latency means that you should be able to access the paste using this url as fast as possible, with very low latency. So the easiest way to find out the non requirement is take a look at 12 quality attributes officers from design, and you will be understanding much more some examples are testability, maintainability, reliability, fault, tolerance. All of these are the non-functional requirements. You can add them to make it much understandable.
Capacity estimation
So now, let’s understand the capacity estimation three things to do that the first one is traffic.
The second one is data estimation. So the third one is the network estimation. So let’s define the traffic before that. We need to come up with some assumption when you’re designing system, you need to understand what will be the user traffic for your system once you have the system running. So, let’s assume that there will be 100k users for a day who is creating new paste on our site so and also assume that if you look at this pattern there is the system looks like more of read heavy because once I paste the content onto my site I might be using the site link to access that page, often enough one or maybe I’m sharing with my friends or some others, so it is more of a real heavy. So if 100k rives are happening or hundred cafes are creating in our system, there could be possibility that it is read ten times on an average, so the reads will be 100 ke to ten, so that will be like thousand k. So using that assumption, let’s understand what is the traffic, so, let’s calculate for the writes for the rice. What happens is we know that 100 k per day rice will be happening so far, it will be divided by 24 will be getting about four thousand one hundred and sixty-six right, spyler so per second, it will be equal to 150 per second. All you have to do is assumption divided by 24, or do it by 24 by 3,600 seconds in an hour, so it will be 150. So similarly for rhys, what we have to do is it is 10 times more okay. So in 210 you will add one more 0 k, so this will be the number of rays or day and then per second. If you want to calculate will have to put the other by 24 by a 3600 and whatever the number it comes up will be, there is per second, it will be obviously ten times more means it will be 115 to ten.
So I can around thousand five hundred reads per second, so this is the expected read traffic to your system, so whatever your design should be able to easily handle this one obviously always keep buffer of about twenty to thirty percent so before it is about thirty percent, that could be means that you might get thirty percent less traffic or your system should be able to handle thirty percent more traffic as well means that we have to design our system may be approximately to meet thousand thirty percent of one point: 1500 is what our own four hundred plus or something so, let’s round off this to around two hundred, so two thousand requests per second, these are read and the rights will be, let’s round off it, to maybe two hundred rights per second, something like that.
Storage capacity estimation
So let’s understand data storage capacity estimation.
So we have to make little more assumptions here. Our business requirements said that we can store maximum of ten in the of paste text data in our system, but not that every user will upload that much of data. That’s a max limit, but most of the users might upload even less or some might upload ten amin max or it could be so we have to draw a middle line number on average on an average. How much the data the every user will use it. It would come around 10 kb, it’s up to you, how you want to derive an average, so I’m just there and get something lower ballpark, so it will be like. So, let’s assume the hundred kb of data on an average. Every user will update in a day or in a year, so that leaves us to estimation. So on our, we have to do two estimations, the worst case, storage and the average case on the worst case is if we store, if every user stores, 10 way of data and in a day, if we are receiving about 100 k rights, then how much data we are going to store so that will lead up to about thousand ge data for a day and the second one is average data consumption, in this case, 100 kb of users on an average 100 kb of data for all the users on an average. In a day and kay rice, so that would give up to about ten gigabytes of data storage per day.
So what does it says and why it is important, is because, based on these numbers, we can decide what kind of database we can use. If you look at, if what, in a day, we are saving about on a worst case thousand gigabytes of data in error, it will be coming up to 365 days in two thousand gb, so f would be looking like 365 terabytes of data in a year. So if you have, if you have plans to run for longer duration, like 10 15 years, that would easily give an estimation of how much data you’re going to your system is going to store on a worst case. But the best case looks really credible or incredible. This is just 10 gb per day. It’s ok, so these numbers will help you to decide what kind of database do you want to use it for your system and what is good, so you can use sql or no sequel.
If you use no sequel now, a lot of things are automatically taken care. Let’s see how we can do that in future? The second thing is so suppose: if the user is storing 10 mb of the data, do we really need to store that information? The database itself? Do we offload that information somewhere in a data storage like s3 or azure cloud data, storage or somewhere, and then do we only say that our friends or the url to that blob in the you know, s3, that’s one strategy. So if, if we go to that strategy, what’s what are little problems? So if you say everything in the db it’s much simpler because you don’t have to make external calls, because once you make the query, you get back the data, but the there are lot of problems with that. So if you are making a lot of queries to the database and along with the query, you are getting too much of data back in that query itself. That means the database I will should be really high because you are doing too much of network consuming too much of network. So one way to solve this has been discussed. We can offload the blobs to the storage, but is it worth to offload everything if the data size is very small, then do we need to so we can do a hybrid approach where, if the data size is less than the average, then let’s store that information along with the data entry for the paste in the as a block, if it is crossing more than the average consumption, then what we can do is we can upload it to s3, and then we can save the link to that s3 in the database. But is that an official? Because if you look at the caching strategy, we are going to discuss in the future, but let’s just further information.
Can we cache all of this 10 mb of data in our caching servers, because we know that the right to read our show, according to our assumption, is one east of 10. So when there are one right happening, there could be that possibility that there are 10 bricks. That means that potentially we will have to catch this. Maybe we are a caching after second request, then we will be optimizing. We are reducing eight writes our sorry reads to our db, so our db will be much healthier, so we need to cache. If we add caching, the problem is: can we catch all the 10 mb of data in the ready system? That will be a huge problematic if we don’t catch it. User will see a lot latency because by the time you download from s3 it takes a little more time to render so what we can do. Hybrid approaches in your database record, so you’re going to store. If your data is crossing more than average you’re going to store, the s3 is linked as well, and also just some 100 kb of data. Also, why? If you have 100 mb, you are just shown in a little bit of data, also in the database, along with the s3 link, so that when the user queries, you can easily show this preview text on his page so that the user will be having some later to look at it and in the background you can make a call to s3 and lowered the remaining data. So that’s like adaptive approach where you show some preview of the data and then in the background we are fetching complete information from mistake, then show it.
If your data is less than the average, then you’re, obviously not storing in the s3. Everything is presenting the database raw pixels, so you can directly show it to them. So this way caching is also much better and also we can efficiently utilize s3 or any data storage distributed data storage to store the big blocks.
Database schema
So the next thing to understand is database schema. In this case we need two different tables. The first one is user. The second one is, the paste information table in the user table will be obviously need for different field, ie name created and some iterator permission. If you want to store so every time the user is logged in you’ll, be creating one entry for that user and in this respective name of the user.
Otherwise, you’ll be creating an anonymous user and you still refer that user by some-some id for that user and that user will not have a name will not have a name or any other information. So this is just needed to show all the created face from that particular session so that, even if he refreshes he can at least see all the paste he created without logging in so that way we can still have some references of who created all of these pastes. So the next thing is, we need paste table. This obviously will have paste id and the content, though the interesting thing is, as we discussed. If we go for hybrid approach, where, if you’re saving some set the content, if only if the data is less than hundred kb, in that case maximum, we need this column to be half 100 kb. Only ten hundred capable care is more than enough and then the s3 link where, if the data is more than hundred kb, that means that we are going to store the s3 link or the object ie of that blob in here otherwise created date and is needed. When the paste is created- and the next thing is expired, this is by default, set to six months. Otherwise, if the user configures to some other information, we can store that here and you guys are fill in whatever the data types and size and then you calculate all of that when you are calculating the estimation, also, so what kind of database to use as the discuss earlier, we can use our dbms, our no sequel in case of no sequel.
We can go for mongodb because it is truly consistent database. As well, and also you can use arguments in that case, you will have to partition by user id or something like that. So we can linearly keep on scaling. Whatever the data we are saving every day and one more thing is people usually think that why can’t we just use redis, where we can store all of this information against a simple key, maybe a paste id and all of this information.
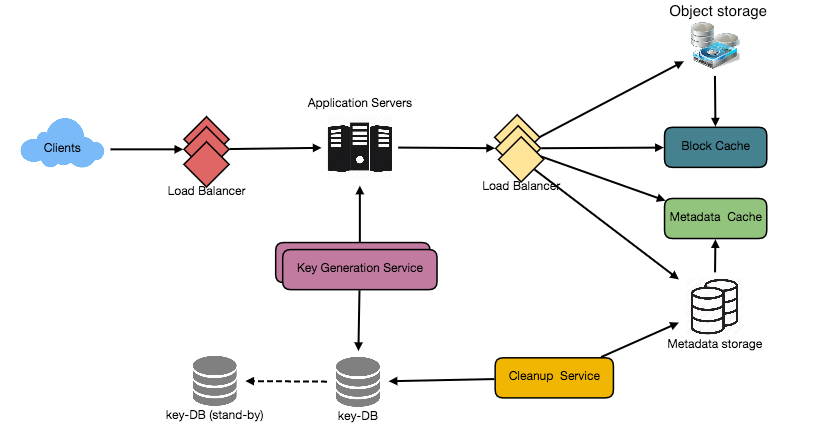
You can do that and it is also high-performing. The thing is you’ll be end up paying a lot of money to your cloud provider, because everything is stored in the ram and ram is to cost year so on. An overall redis is too much costlier compared to the database, because database is disk, oriented and now here’s the system, design, diagram for pay spain and how it is design.
System design diagram
A nice thing so two way you can do that one using server lists. Okay, this design is totally written thinking. It has a serverless design, but you can do by using your virtual machines or containers as well, so in this case I’m using a paying it way, because these are server. Let’s say in case of amazon eight appears it will be considered as lambdas. We don’t need too much of back-end functionality here, apart from, if you look at the eps, we need one is the right api for the paste and one more aka to read that paste, whatever it is between two system. Apart from that, you can have other aps, like user specific, like user creation, api or update ea k. All of that so now what happens here is the api gateway every, since the request from the user’s browser or application, and then it is going to invoke as many server less functions it needed. So you don’t have to really worry about scaling and all of that, but if you don’t want to use server less strategy, what you can do is you can have as many containers here you can maybe use who volunteers or droppers form or something like that? The idea is, you will be having those many container.
The server’s are easy to. Containers are easy to instances whatever it is, so you’ll be having those many in that case, most likely of read and write pay functions will be the same code base, so any containers or any or chilled machines or ec2 instances can handle both thing. So, in this case, I just wrote it separately because those are several less functions. So when the request comes in, it is going to invoke those many so those many lambdas or functions and those will take care of writing the data into the database over here. And these databases are partitioned by user id, and this is a range partition where initially we’ll be having only one say, for example, if here designated the range from 1 to maybe 1 million until it reaches from 1 to 1 million, all the data rights will be going in here- and you will be always having a you know way of monitoring that you always have 50% extra space available in your system. So once you know that there is, it has filled up by 50%, you always keep provisioning the extra database and then keep us in the next ranges for the partition. So the the lights always kind of keep going on to one database and since our lights are like 150 to 200, writes per second. These databases can easily handle if it is no sequel other, it would have been in a ring configuration or it is already distributed.
So the lights would be automatically going there. So this is what it is. If you want to design it as a microservices, then definitely your one container or couple of containers or ec2 instances will be taking care of only the bytes of paste and then creating and those will be connecting to this database, and that could be one more micro service which basically waves all of the paste which pasted into the database when the request comes in so the other thing you need to look at over here is. We have used memcached as well, because we want to cache some of the pastes, which are frequently accessed, as we are clear discussed that the read verses right, oh sure, is 10 is to 1. So so, if there is one right happening, that most likely pen reads are happening in parallel, so the we have to scale this section more than this one. If it has service functions, then you don’t need to really worry about it, so that will be automatically plated, but if it was ec2 instances or virtual machines. So if you have maybe one instance of this, maybe you need ten of them, but it is not always straightforward. You will only figure out when you do. The load testing observe that so in case of caching. Here, first, what happens is that when the request comes in, you will check in the cache.
If that value or keep a new presence, then if you reach there, you don’t need to query the database and then it can just get it and then return it. If there’s a cache miss, then the request will go to the database and get it back and then cache it over here, and then they turn it back and also one thing you need to see over here is: it is also replicated since we know that memcache is is very good in performance because it’s multi-threaded, unlike redis, so we want high performance over here and also it supports clustering. So we have multiple nodes in this cluster and all of them are replicated. So you don’t lose the data as well, so I, don’t you most likely once you write the data into the cache most I think you will not not be getting the cache, miss and also one more strategy we discussed to optimize. The caching is because cache is costly, all right, so the other optimization we discussed other is. If the data is more than 100 kb the average size, then we are going to upload all of that data into the block store here. It could be s3 or it could be anything on the cloud which is a distributed store for the block. So we also store a little bit of preview data into the database and the order of the data will be stored in here and that you are will be recorded into the database and when the user accesses it.
So you can get the entry of preview of 100 kb data and all the other information send it back here by the real api and the complete information can be queried from the s3 over here and then you will have a complete here, and the next thing you to understand is the freedom of choosing the length here, I’d like it’s a unlike this system.
This is not really a url shortener, because lot of I’ve seen a lot of documents lot of articles in the internet. They all refer. It is something similar to you know: url shortener, but maybe a little bit is true, but not everything, because here a lot of things changes here, because we don’t always comes. We don’t have a constraint of choosing a very short key here. We have the freedom of choosing a needle end, but it’s always advise to use a short one so consider if we just use about 10 10 character, length based identifier, then we have the freedom of if we choose all the 64 characters like a to z, small letter a to z 1 to 10 and the special characters, whatever it is, so we’ll obviously have 64 of character. Freedom so it writes to the power of 10 character. Whatever that number is, it will be definitely millions, so you will never run out of these random text to choose it for the paths so so, but but the thing is, who will create these keys and how these unique keys are referred? One strategy is: let the database create the keys for you itself, but the problem with that is, the databases will usually create. You know the keys serially. That means that the numbers are from 1 2, 3 4, something like that.
That is more predictable. We don’t we don’t want users to able to predict the paste say, for example, if you use the database key directly sell our first created. Paceman will have the url something like dot-com slash one and the next one will be 2 3, 4, 5 6, something like that but use it. So any hacker can easily hand not just factor. Anyone can easily predict the pace, so they can keep on incrementing. The number and then keep on reading whatever random test, so we don’t want that. So we want to have this one of always equal length and so we can’t just collect database, create those for us, so we’ll have to manage to create that one. So one easy strategy is: let this api itself create a random number and try to insert the information which we want to insert into the database with that randomly created string of a certain length, then, if that key is not already present in the database, then obviously the write will be successful because we will be having the unique constraint for the for the primary key or id of the paste, so it will go through if it raises to duplicate error. That means that that key is already used, then we’ll have to recreate or regenerate a new random key and then try to write it and then, if it succeeds, fine, otherwise we’ll have to come back in and click create and then write it. This is easier because I’ve seen some of the comments in my previous video that, in case of your short nur, then why are we using zookeeper for creating the ranges of ii’s? Why can’t we just do this way like creating the random string, try to write if it is already existing, then we will create one more and then keep on writing the problem with that strategy. Is them when you have already utilized a lot of randoms keys, most likely that you will be creating random string strings which could be potentially clashing the existing, which could be potentially clashing with the existing key, which is in the database?
So we don’t want that. The reason is simple, because we will usually have an sla of okay. We are going to come complete. This write request in certain specific time say: yeah sla says that we are going to finish this right, maybe in say 200 milliseconds. In that case, out of the 80s, most likely should be finishing in 200 millisecond. But if you look at this case when we are randomly creating in this api and then writing into the database, sometimes if there is a cache sorry sometimes if the keys are colliding or there is a clash, that means that will have to come back and create one more and then write it again, keep on writing right.
So that way we spend most time over here doing that operation. So our api is cannot complete a compliance to the sla today? Is service level agreement. So then what happens is sometimes the a case will be faster and sometimes they will be slower when there is a id clash. That means that the case will be taking more time to figure out the next one and then try to write. So this is not really a good way of doing it, so our system should we always be predictable, and so that’s the reason why we also need to have one more service which actually generates keys for us. So that way, we don’t really need to worry about generating the key checking into the database.
Is it flashing with a already stored data or not, and then figure out one more and do that, so our key generation service will take care of that work for us. What we have to do is maybe make an rpa rpc call or something from our lambda function earlier ec2 instance to ask for our keys annuities. This service will basically would have already generated a lot of keys ahead, maybe we’ll be having multi-threaded operations here. One thread will be keep on generating a lot of keys for us, the other two, it will be suffering back. The keys to be all the services which are the custom for all the children will be keys, will be stored in the radius and it is also distributed so that we don’t lose those keys and we have a track of what keys are used and, what’s not, and if you look at this, even if you have billion number of keys, the memory which we need is very less say if we have 10 character, ok, 10 characters into maybe whatever this number comes up to, even if it is like hundred billion whatever. So it would never cross more than a hundred gb, and this is very negligible, considering that we just need 100 gb off, all right is storage 2 for our key generation service. So that way, there is a service which automatically generates keys for us and all of the they write. A key is will be keep on asking the key generation service to give our unique key and then take that he’ll then keep on writing or maybe to optimize. These servers, maybe requesting for hundreds of you know keys at once, and this service will mark all of the hundred has used, and then this service would be keep on using those hundreds of keys at once and then once those are over, they keep on asking the key generation services. That way, we can reduce the number of calls coming to the distributed key generation service over here, and this distribution distributed key generation service is also replicated, so you can have master master master slave like architecture over here is just very simple. If this machine is down, maybe this way I will talk to this one, because our of the data will be present in the radius, and this is already distributed and persistent.
So we don’t really need to worry about it’s not too complex to implement over here.
The next thing to understand is how the distributed key generation service will generate that random strings. This design is taken from twitter snowflakes, where twitter used to also have distributed key generation service to generate the keys for the tweet priests because they used to use cassandra as the database and cassandra. That time doesn’t use to support the auto incremental id for the new records or the rows to be inserted in the into the table. So what they used to do is distribute key generation will generate a keys for those tweets and that will be unique and those keys will be used as the primary key for those tweets and the same concept. We can use it here. This disability generation service will be keep on generating a lot of keys for us. We can have two threads over here, and one thread will basically takes care of providing the keys to the any any service which asks to provide the keys and the other thread. What it does is it keeps on generating these keys and then storing it in the redis and marking them as not used. Okay. So that way, the other thread when they want to provide the keys they can check in the gate, radius that whether this key is used or not. So that way, we know for sure that this is not colliding and, most likely, since we are using time staff and all of the a different thing, it will not collect but if you want to make sure that this is colliding or not, you can just use radius and it will never cross.
As we already discussed, this will not cross a couple of chippies, because, even if you are using millions of keys, it takes only hundred gb because we’re just using eight capitols. So how do we turn it this case to regenerate this piece? We need a combination of three different parameters away. So first one is millisecond precision, epoch time that will consume about 41 bits of your memory and then the node id. So then order these are the ids which are assigned to the neutral nodes of your decision region service from there you take ten bits of it, and then you need a local counter. A counter will be running in each of the distributed key generation service service. To make these keys much randomized, so the counter will be running from zero to four thousand, whatever that 48 or whatever. That is equal to two to the power of 12. Okay, so two to the power of 12 is equal to whatever the number I. Don’t remember it right now, so until then, the counter will also be running running and every time you generate a key, the counter will be incrementing, so you make the combination of all of that, and one bit is less because to make it 64-bit because it can’t have 63 bit.
So so add one wait: maybe you can use this for a future purpose for something else, so the mean total. You will get 64 faith, which is always unique at any given point of time, and this way you can generate a lot of keys whenever you need it, so this is all about distributed key generation cells.
Expired data
The last thing we need to understand over here is how the data is expired or how the each individual pastes are expired after the expiration time. For that, you will need to have another service called cleanup as a sink a synchronous service, and this service is totally independent, and this is not going to talk to any of the service except the database itself. What happens to that service is basically. This will keep on waking up every once in one hour or something like that. And then keep on checking all the records in the database to check if there are any records whose expired time in the database is much lesser than the current time. If that time is lesser, that means that that particular paste is expired.
What we can do is it can simply delete that particular row along with the deleting deleting the record in the database. If it has a s trilling, then you can go back to lock, store and delete a record from the block store as well. That way, we will save a lot of money if we took, if you forget, to delete that from the s/3 s/3 will be keep on charging for you as well, so we have to clean up there as well. I think I have covered all of the scenarios. You need to understand for the paceman service yeah, if you liked this video, please hit the like button and if you have any questions, please comment: I will try to answer in my free time and I’ll try to leave the system design diagram in the description. Thank you
Course Instructor
This course does not have any sections.